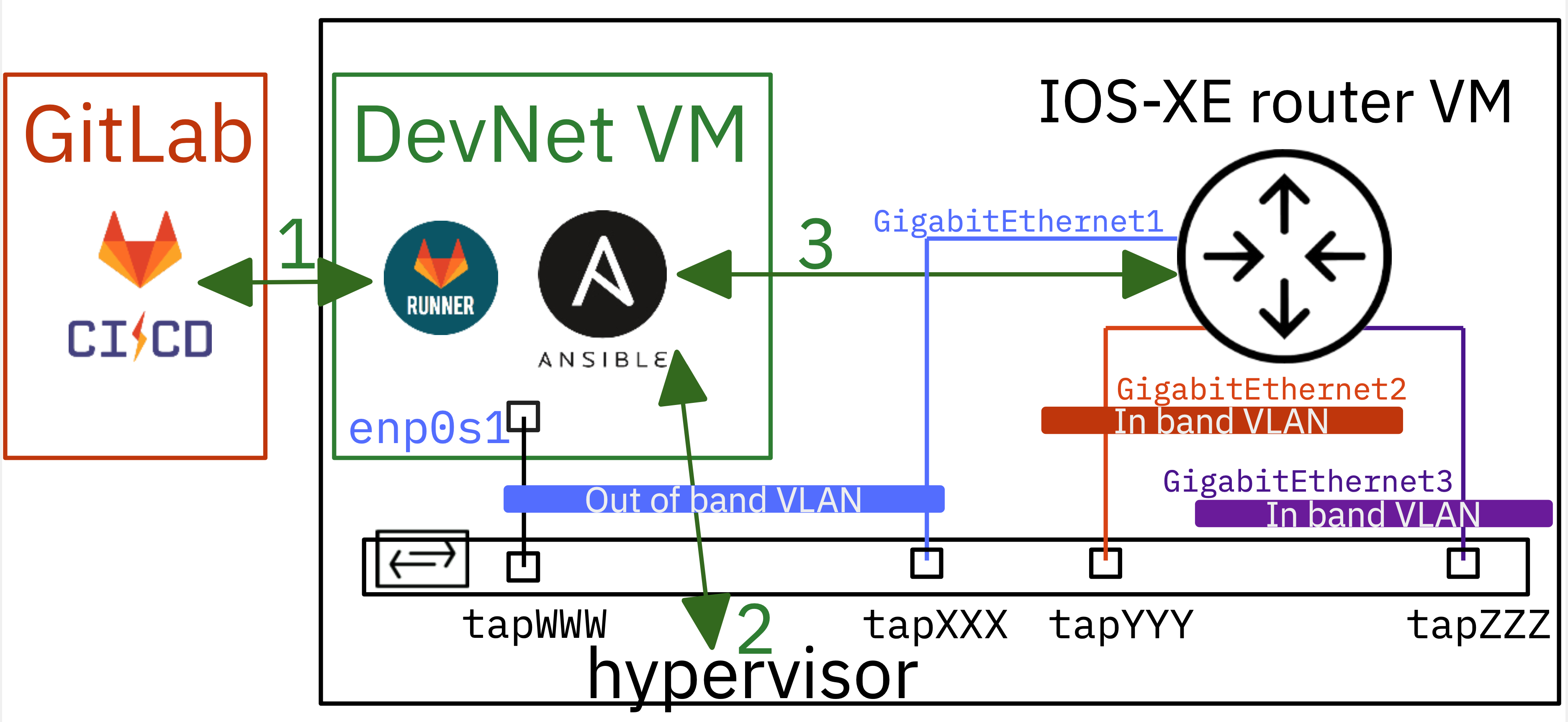
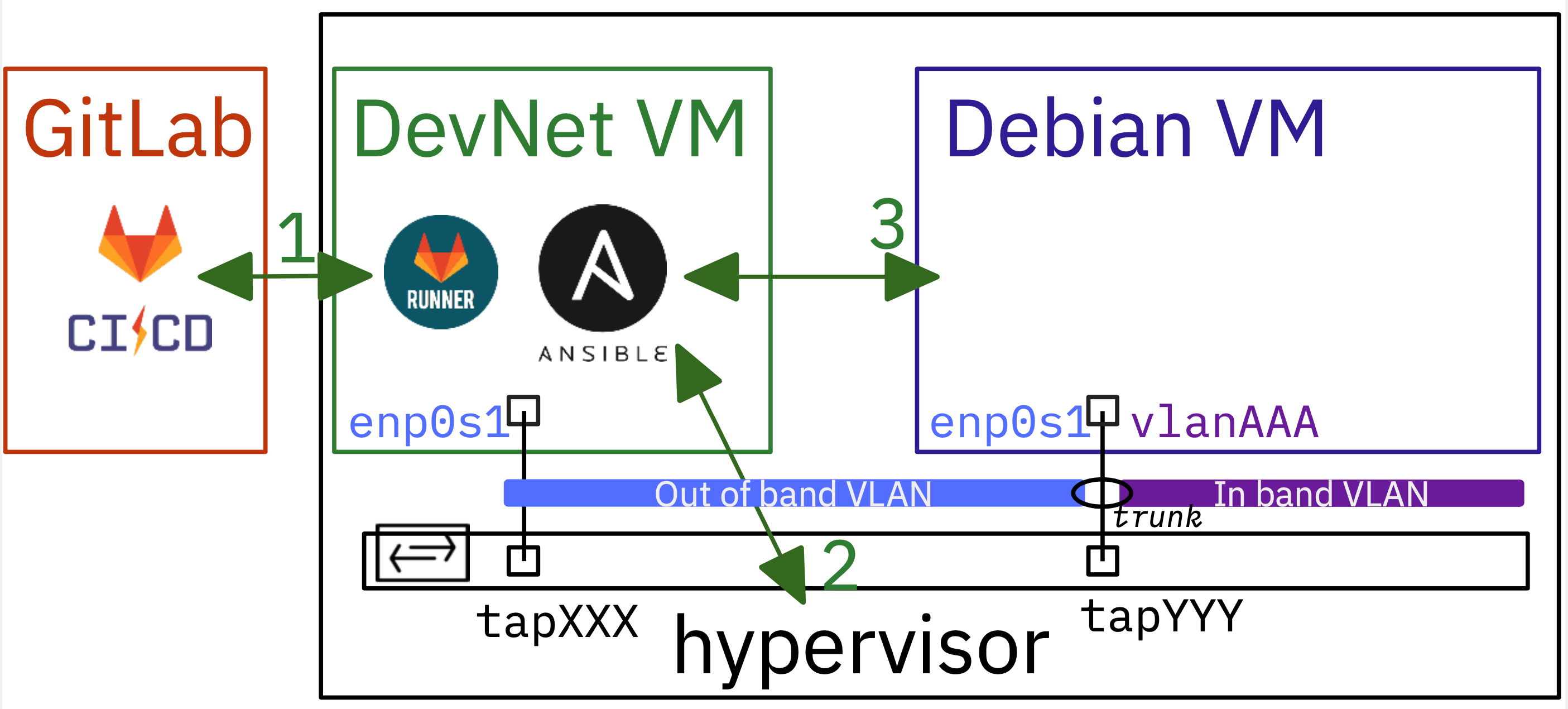
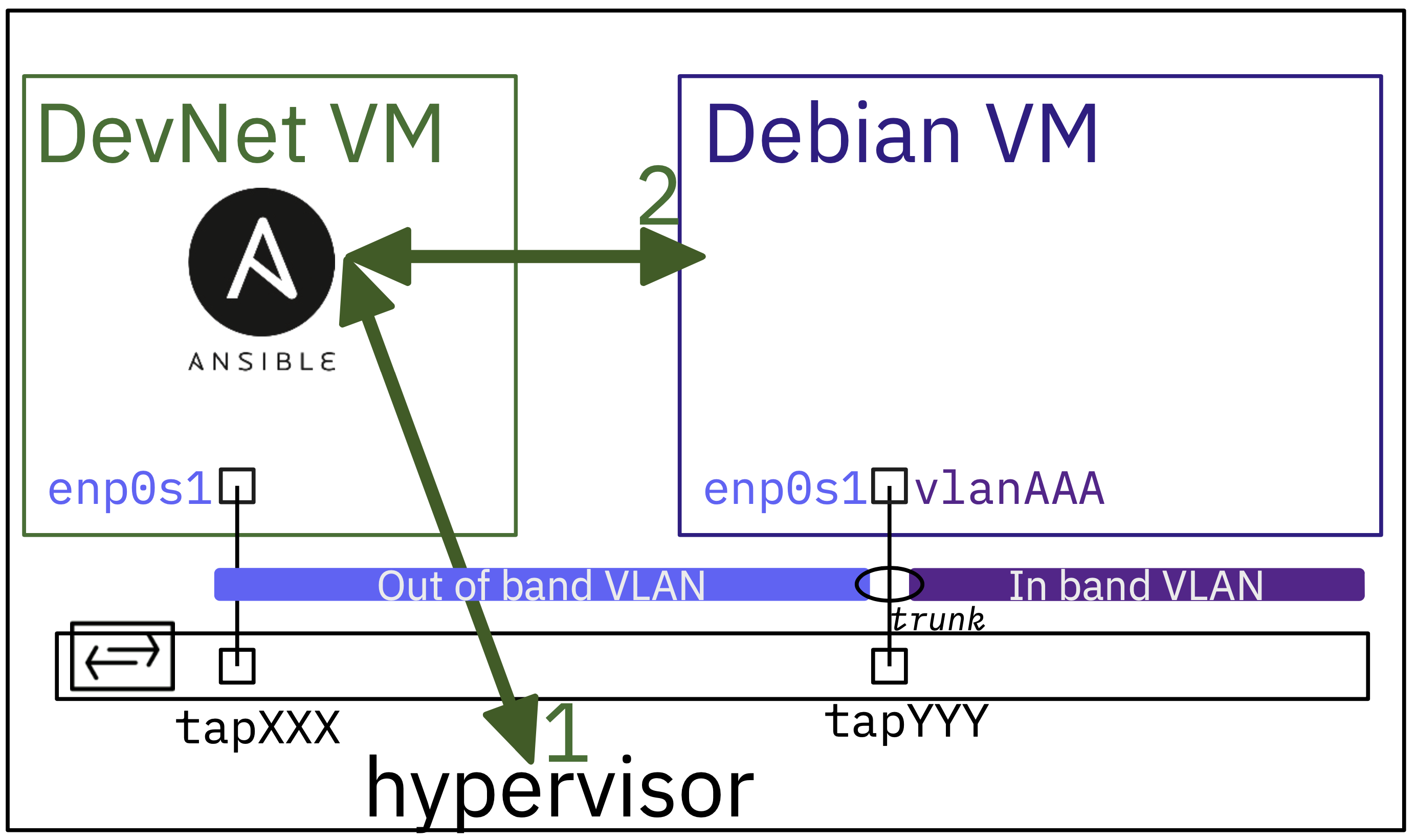
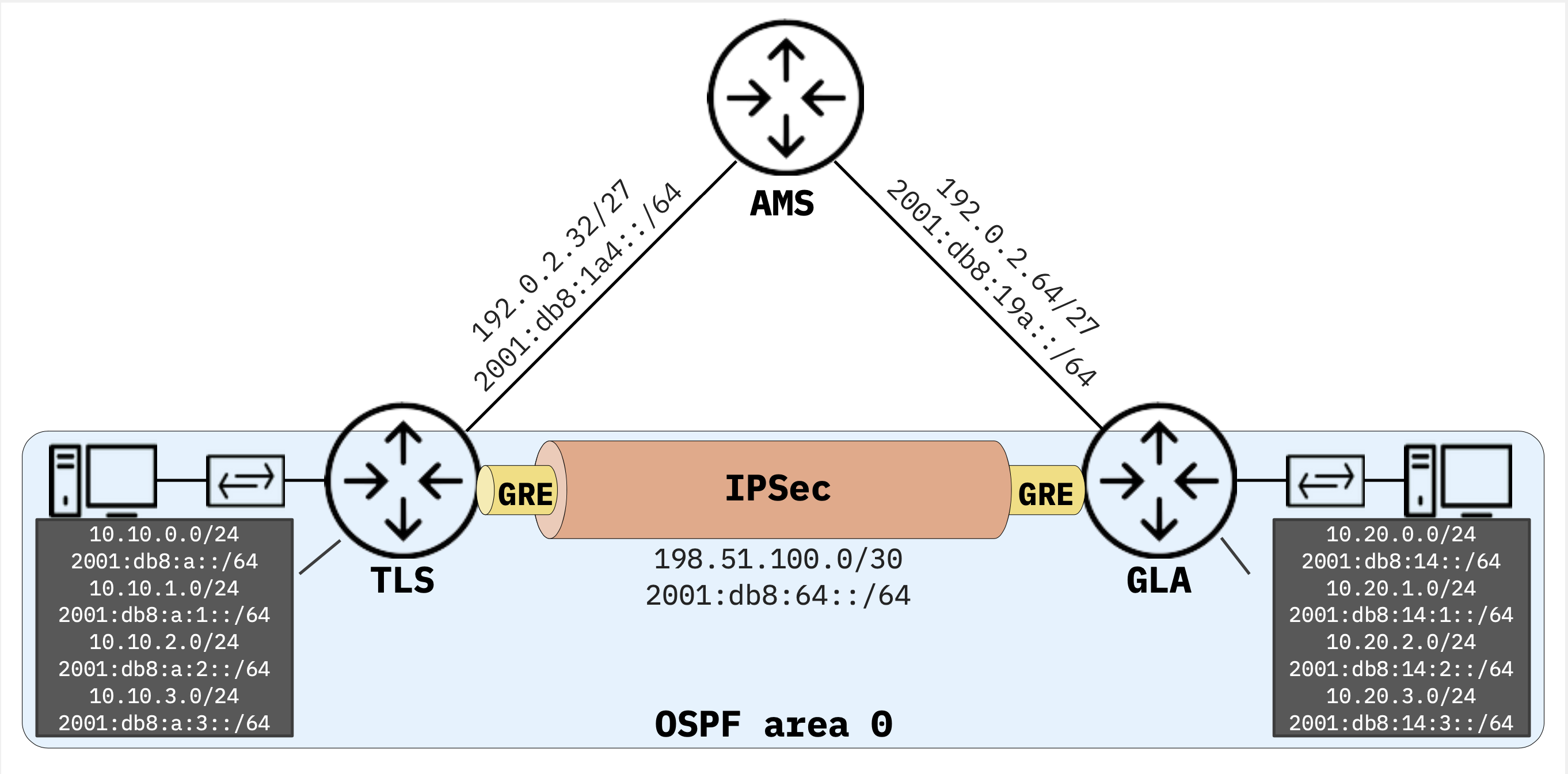
Comme de plus en plus d'images de machines virtuelles de l'hyperviseur KVM
utilisent l'EFI à la place du BIOS historique, j'ai ajouté de nouveaux scripts
de lancement dans le dépôt GitHub : inetdoc/guides/vm/files/.
Il faut ajouter que Cisco fournit aussi les images de routeurs CSR1000v et
de commutateurs Nexus9000v avec un lancement EFI.
Cette nouvelle gestion de l'amorçage système s'appuie sur les fichiers
fournis par le paquet ovmf. À chaque lancement de machine virtuelle, un
lien symbolique vers le fichier OVMF_CODE.fd est créé dans le répertoire courant. On ajoute à ce
lien une copie du fichier OVMF_VARS.fd avec le nom de la machine virtuelle en préfixe.
Le nouveau script ovs-startup-efi.sh
décrit deux unités de stockage au format pflash pour chacun des deux fichiers.
Une fois la machine virtuelle lancée, on obtient un montage avec une partition EFI.
$ ./scripts/ovs-startup-efi.sh vm0-debian-testing-amd64-efi.qcow2 4096 0
~> Virtual machine filename : vm0-debian-testing-amd64-efi.qcow2
~> RAM size : 4096MB
~> SPICE VDI port number : 5900
~> telnet console port number : 2300
~> MAC address : b8:ad:ca:fe:00:00
~> Switch port interface : tap0, access mode
~> IPv6 LL address : fe80::baad:caff:fefe:0%vlan68
$ ssh etu@fe80::baad:caff:fefe:0%vlan68
Warning: Permanently added 'fe80::baad:caff:fefe:0%vlan68' (ED25519) to the list of known hosts.
etu@fe80::baad:caff:fefe:0%vlan68's password:
Linux vm0 5.16.0-1-amd64 #1 SMP PREEMPT Debian 5.16.7-2 (2022-02-09) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
You have no mail.
Last login: Wed Feb 23 09:11:33 2022 from fe80::5449:9fff:fe63:95ba%enp0s1
$ mount | grep efi
efivarfs on /sys/firmware/efi/efivars type efivarfs (rw,nosuid,nodev,noexec,relatime)
/dev/vda1 on /boot/efi type vfat (rw,relatime,fmask=0077,dmask=0077,codepage=437,iocharset=ascii,shortname=mixed,utf8,errors=remount-ro)