Les manipulations proposées dans le support de travaux pratiques DevNet Lab 9 – Configure Open vSwitch using the Python ovsdbapp library , s'inscrivent dans le domaine de la programmabilité des réseaux. Associée à l'automatisation, la programmation des topologies d'interconnexion de réseaux est devenue indispensable pour répondre aux besoins d'agilité, de fiabilité et d'évolutivité des infrastructures modernes.
La problématique étant posée, nous sommes à nouveau confrontés à des défis de taille !
- Nos étudiants, bien que débutants, ont été habitués à l'approche impérative (séquence d'instructions propres à chaque constructeur). Le passage à une approche déclarative, qui décrit l'état souhaité sans tenir compte des équipements cibles représente un changement de paradigme important.
- Dans le domaine de la formation, on privilégie souvent des solutions qui escamotent l'infrastructure physique sous-jacente - underlay network- qui assure la connectivité de base, pour se concentrer sur l'abstraction d'infrastructure - overlay network- qui offre une grande flexibilité pour les applications et les services. À force de recourir à tous ces faux-semblants, les étudiants ont du mal à changer de contexte, et certains pensent même que c'est impossible.
Si l'on fait le choix de ne pas former de jeunes narco-dépendants aux grands fournisseurs du cloud public, on n'a pas d'autre solution que de se plonger dans les opérations avec un niveau d'exigence élevé en matière d'automatisation.
C'est ainsi que le support de travaux pratiques DevNet Lab 9 propose de produire un code Python de configuration des ports d'un commutateur virtuel Open vSwitch (unique pour débuter) à partir du contenu d'un fichier de déclaration YAML.

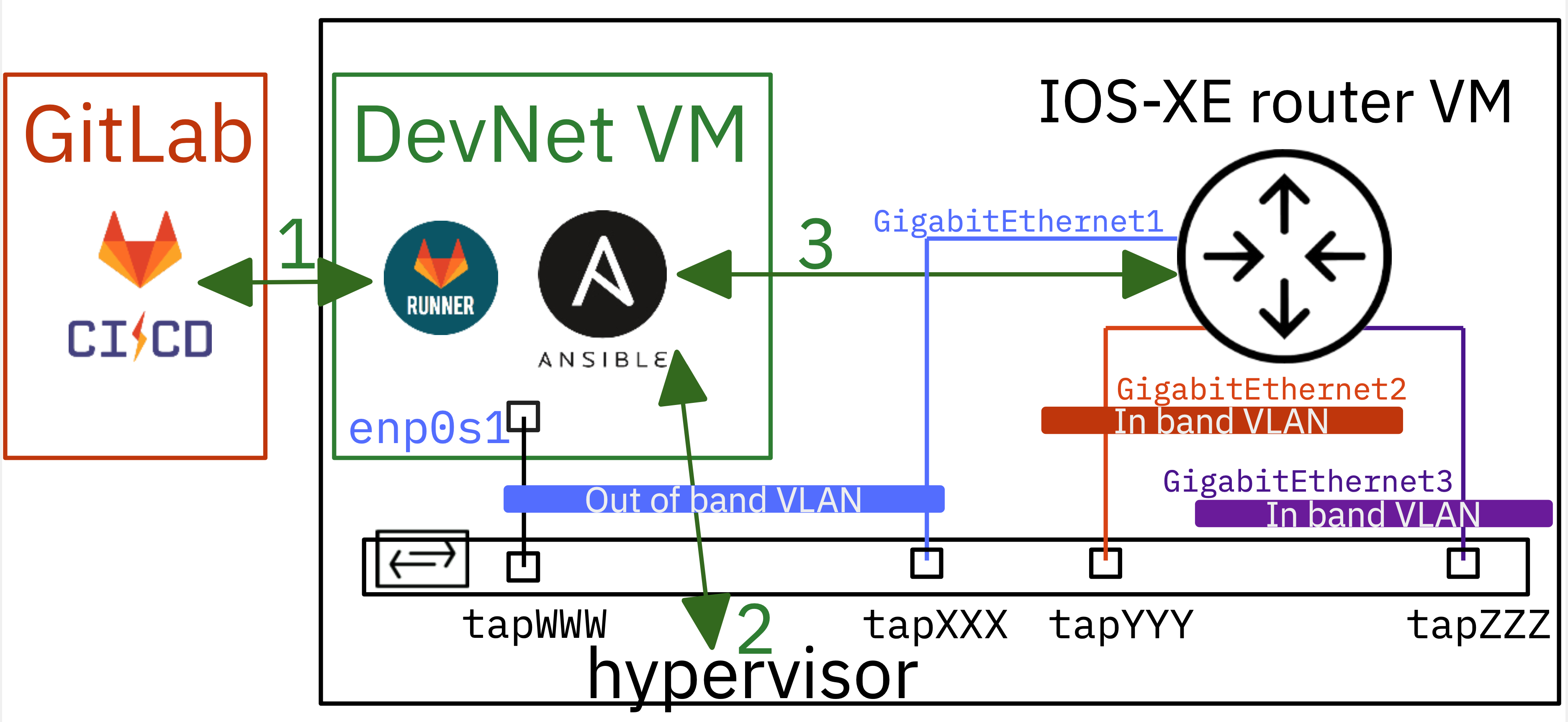
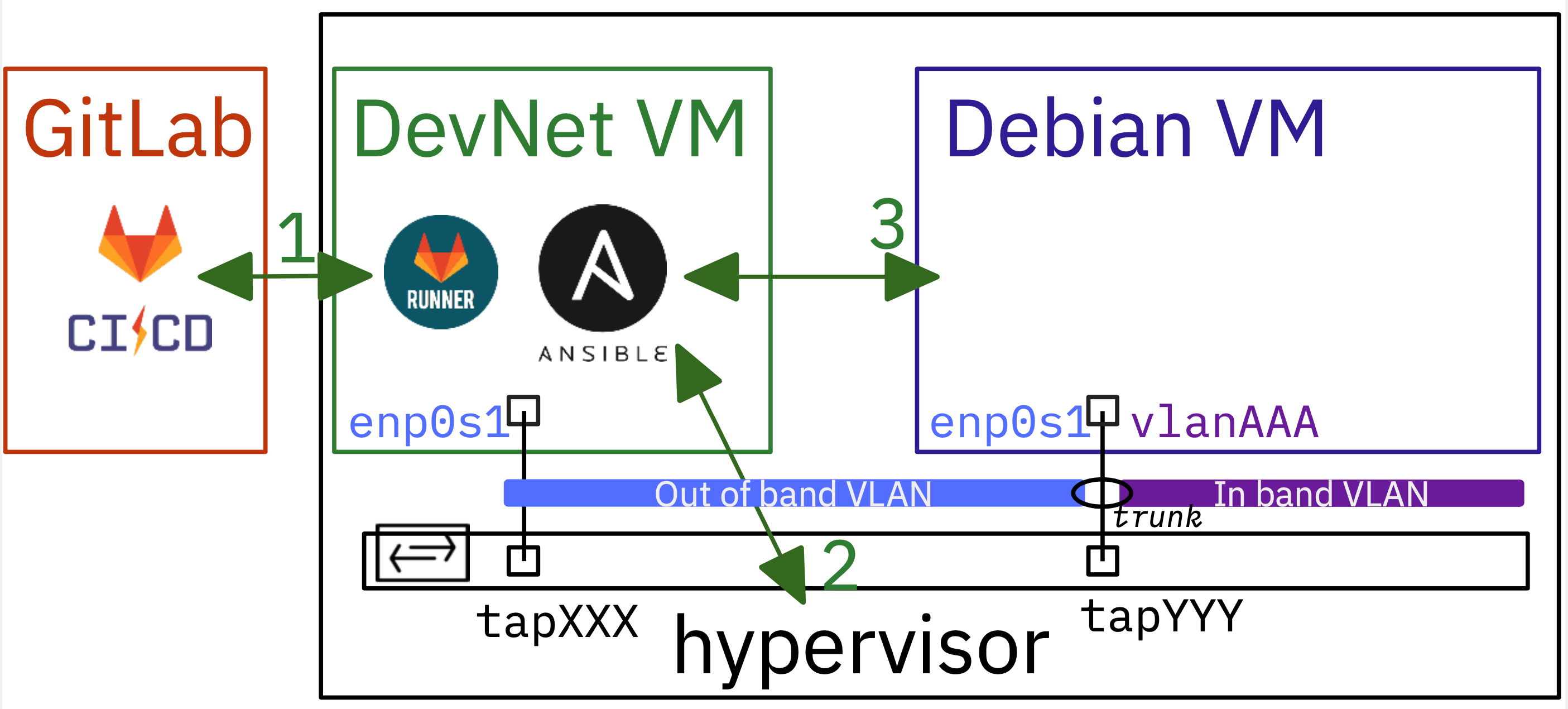
Les manipulations s'appuient sur un scénario concret : dans le contexte d'une infrastructure cloud privée, des hyperviseurs sont déployés avec chacun un commutateur de distribution Open vSwitch nommé dsw-host. Un grand nombre d'interfaces tapsont provisionnées et déclarées comme ports de commutateur. Lorsque les étudiants démarrent leurs premiers travaux pratiques, ils se voient attribuer des ensembles de ces interfaces pour exécuter des machines virtuelles ou des routeurs. Il s'agit donc de programmer les topologies réseau d'interconnexion entre le monde virtuel et le monde physique.
Les objectifs du laboratoire sont simples :
- Établir une connexion sécurisée au serveur de base de données OVSDB à l'aide d'un premier script Python
- Lister les commutateurs existants et récupérer les attributs détaillés d'un port particulier
- Charger et appliquer des configurations réseau depuis un fichier YAML vers les ports du commutateur
- Vérifier manuellement les configurations appliquées sur l'hyperviseur afin d'assurer la cohérence entre l'état déclaré et la configuration réseau réelle
La progression des manipulations est organisée en trois parties principales, chacune apportant un niveau supplémentaire de maîtrise :
-
Mise en place de l'environnement
Cette première partie analyse les conditions nécessaires pour établir un canal de communication sécurisé entre le code Python et le service ovsdb-serverexécuté sur l'hyperviseur. Les étudiants apprennent à utiliser la fonctionnalité LocalForwardd'OpenSSH pour créer un tunnel sécurisé vers le socket Unix du service. -
Exploration interactive avec Python
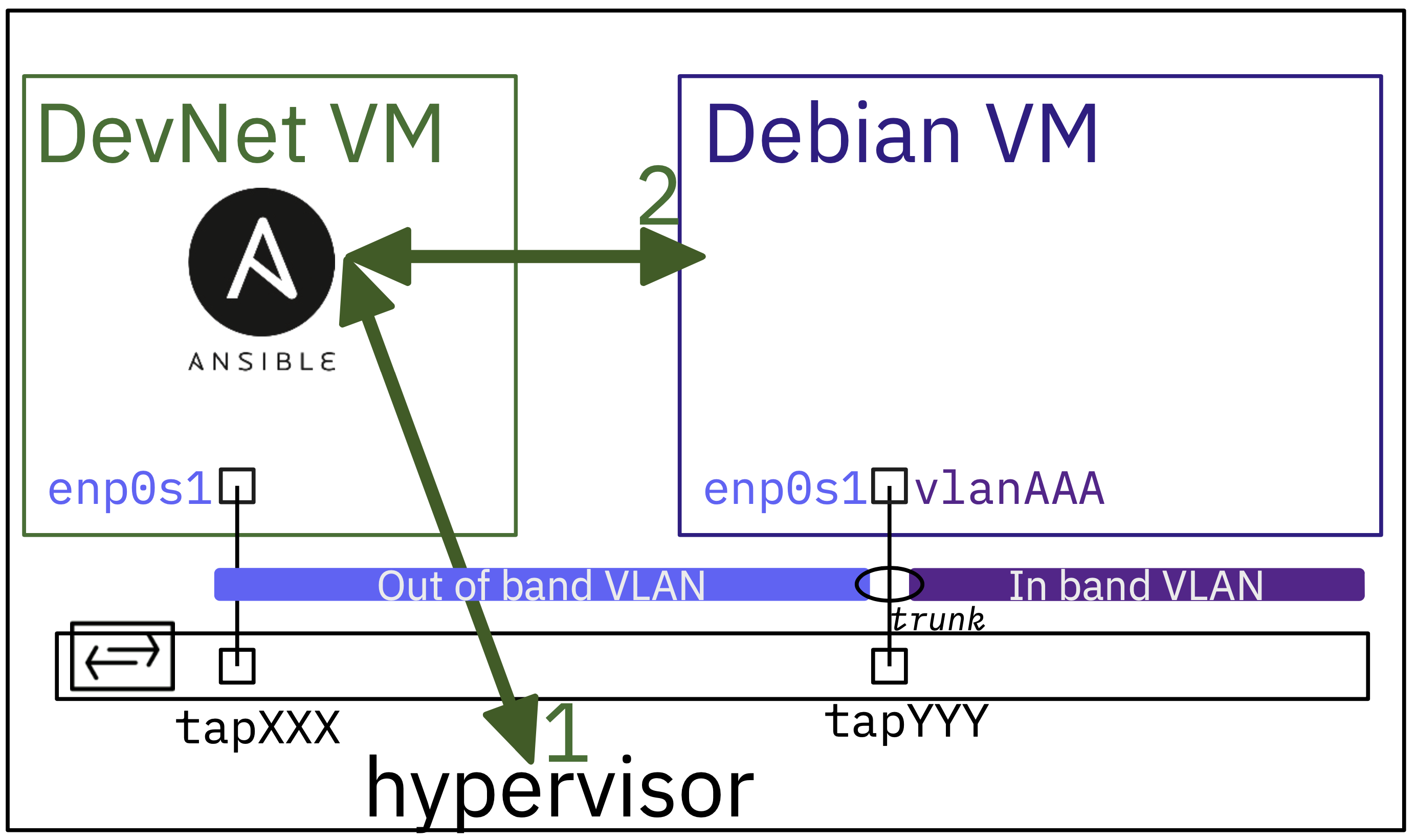
Dans cette deuxième partie, les étudiants apprennent progressivement à interagir avec la base de données Open vSwitch. Ils commencent par une simple liste des commutateurs disponibles, puis récupèrent les attributs détaillés d'un port spécifique, et enfin analysent les configurations VLAN (mode accessou trunk). -
Évolution vers une approche déclarative
La troisième partie introduit l'approche déclarative avec YAML comme source de vérité pour la configuration souhaitée. Les étudiants développent un script capable de charger cette configuration et de l'appliquer aux ports du commutateur. Ils implémentent également un mode " dry-run" pour prévisualiser les changements sans les appliquer.
Cette approche progressive permet aux étudiants de comprendre d'abord les mécanismes sous-jacents avant d'aborder les concepts plus avancés de programmabilité réseau. Néanmoins, elle comporte certaines limitations.
- L'environnement de laboratoire requiert le maintien d'une connexion SSH active entre le système de développement et l'hyperviseur.
- La courbe d'apprentissage associée à la programmation Python et aux concepts de réseaux virtualisés est assez abrupte pour les débutants.
- Les concepts de cache et d'optimisation des requêtes introduits dans la dernière partie peuvent être difficiles à appréhender sans une solide compréhension préalable de Python.
Heureusement, les étudiants de première année de Master ont déjà parcouru un long chemin dans le domaine du développement. Malgré ces limitations, ce laboratoire est une opportunité de progresser dans la compréhension pratique de la programmabilité réseau moderne, alignée sur les pratiques DevOps actuelles.
Ces manipulations constituent une première étape vers la maîtrise de la programmabilité réseau. Elles posent les fondements nécessaires pour aborder des sujets plus avancés comme l'orchestration multi-équipements ou switch fabric.
Les compétences acquises permettent non seulement d'automatiser des tâches répétitives, mais aussi d'adopter une approche plus systématique et fiable de la gestion des infrastructures réseau - ne serait-ce que pour réaliser les manipulations suivantes. La transition vers le « réseau en tant que code» ( Network as Code) représente un changement de paradigme aussi important que celui du DevOpspour les applications et les services.